平行演算法
期末報告
PVM
應用數學系研一
8524621
韓天祥
概論
在
PVM上,作排序問題,以不數量的資料以及不同數目的slave task 觀察其執行所需要的時間,並討論其結果.
PVM
的介紹
PVM (Parallel Virtual Machine)
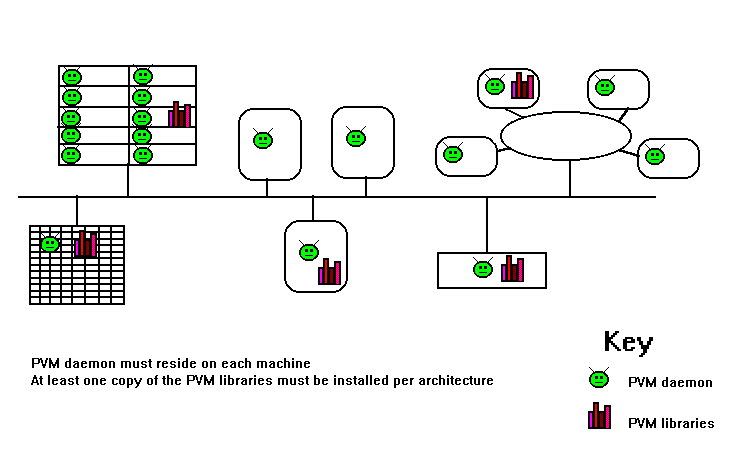
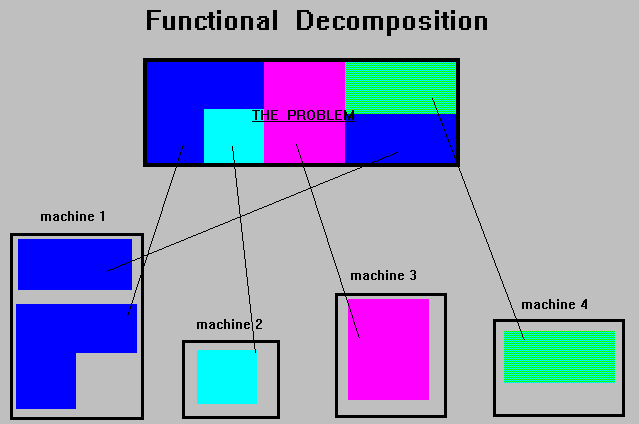
是一個讓大量的 Unix 電腦系統透過網路連接在一起模擬成一個單一的大型平行處理電腦.所以大型的計算問題可以更有效率的運用更多的計算能力及記憶體
.PVM 相當具有可攜性. 原始程式可由網路上取得,而在不同的系統上安裝.
PVM
的優點
PVM
的缺點
PVM
證明了一個message-passing system可以在網路工作站上"有效" 運作的經驗。目前的
PVM系統尚不能達到真正高效能計算 (Tera/Giga Flops), 需要PVM系統進一步的改進.但一般中級計算 (Middle Computing) 可以考慮適合Coarse Granularity大的程式 要利用PVM的異質計算能力,使用者必需在觀念上有所調適PVM
極易學習,並且因為使用者眾多,較其它message-passing系統 的發展有較易信賴的承諾各種工具程式,程式庫是同類軟體最多的
程式的架構
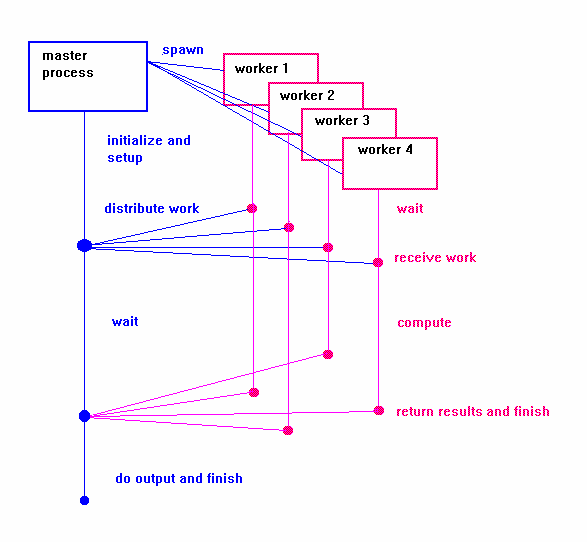
由一個
matser 及數個 slave tasks 之間,互相傳遞訊息,而每個 slave 先將本身的資料排序完畢,而後藉由 broast 的方法將資料傳給其他的 slave , 每個 slave 將接收到的資料與本身的資料比較後可決定出每一個 data 的 order ,最後,所有的 slave 將資料以及其order 傳回 master , master 即可以知道所有 data 的順序.
效果平析
|
|
100 個整數 |
200 個整數 |
300 個整數 |
400 個整數 |
|
1 virtual machine |
* |
* |
* |
* |
|
2 virtual machine |
1.00 sec |
1.00 sec |
1.00 sec |
1.00 sec |
|
更多的 virtual machine |
* |
* |
* |
* |
本次程式只以一台
IBM RS6000 為主機,來模擬多台主機來產生多個 slave task, 但是再本次作業中可以發現效果並不如預期中的理想,在 slave task 方面只能以兩個來執行,一個以及超過兩個的 slave task 在編譯時期皆能正常無誤,但是執行時不管資料的數量大小,執行的時間過長,只好中斷!而本次的
sort,在早上最多可跑 1600 個資料,但到了下午,最多只能在 400 與 500之間徘徊.1600 個資料所執行的時間是 2.00 秒, 而數十個以及數百個資料量所需執行的時間是 1.00 秒,這顯然是因為執行的速度非常快,所以不能有效的分析比較其意義.將執行的的次數增加
,是另一個值得嚐試的方法.但實行後發現,pvm 所 spwan 出的slave task 在程式結束後,並不會自動消失,必須以手動方式來處理,所以只能處理較小資料量的作業,這一方面應該是作業系統方面所造成的遺憾!!